参考资料运行时间测量C++ 实现方式C 实现方式获取数组长度字节对齐大端小端变长数组赋值运算符方法优先处理自赋值PIMPL 指向实现的指针主要优点使用场景示例RAII资源管理状态管理总结心跳实现应用层自己实现的心跳包 TCP 的 KeepAlive 保活机制warning: operation on 'i' may be undefined [-Wsequence-point]严格弱序什么是严格弱序?严格弱序有什么用?严格弱序的三条要求非严格弱序方法带来什么问题?
参考资料
运行时间测量
C++ 实现方式
xxxxxxxxxxusing MilliSeconds = std::chrono::milliseconds;using MicroSeconds = std::chrono::nanoseconds;using NanoSeconds = std::chrono::nanoseconds;template<typename TimeT = MilliSeconds>struct Measure{ template<typename F, typename ...Args> typename TimeT::rep Execution(F func, Args&&... args) { auto start = std::chrono::system_clock::now(); // Now call the function with all the parameters you need. func(std::forward<Args>(args)...); auto duration = std::chrono::duration_cast< TimeT> (std::chrono::system_clock::now() - start); return duration.count(); }};class Dummy{public: Dummy() = default; ~Dummy() = default;public: void Add() { double sum = 0.0; for (int i = 0; i < 8000000; ++ i) { sum += 1.01; } }};void Add(){ double sum = 0.0; for (int i = 0; i < 8000000; ++i) { sum += 1.01; }}int main(){ Measure<MilliSeconds> measure; std::cout << "1. call directly" << std::endl; std::cout << measure.Execution([&]() { double sum = 0.0; for (int i = 0; i < 8000000; ++i) { sum += 1.01; } }) << " ms" << std::endl; std::cout << "2. call member function" << std::endl; Dummy dummy; std::cout << measure.Execution(std::bind(&Dummy::Add, &dummy)) << " ms " << std::endl; std::cout << "3. call common function" << std::endl; std::cout << measure.Execution(Add) << " ms" << std::endl; return 0;}输出
xxxxxxxxxx1. call directly32 ms2. call member function34 ms 3. call common function47 msC 实现方式
xxxxxxxxxxint main(){ clock_t begin = clock(); // your codes double sum = 0.0; for (int i = 0; i < 100000000; ++ i) { sum += 1.1; } clock_t end = clock(); double elapsed_sec = double(end - begin) / CLOCKS_PER_SEC; double elapsed_ms = double(end - begin) / (CLOCKS_PER_SEC / 1000); printf("elapsed %.3f second, %.0f ms\n", elapsed_sec, elapsed_ms); return 0;}输出
xxxxxxxxxxelapsed 0.360 second, 360 ms获取数组长度
xxxxxxxxxxtemplate<typename T>size_t GetArrayLength1(const T &array){ return sizeof(array) / sizeof(array[0]);}template<typename T, size_t N>size_t GetArrayLength2(const T(&)[N]){ return N;}int main(){ int array[] = { 1, 3, 4, 5, 7 }; std::cout << "Length: " << GetArrayLength1(array) << std::endl; std::cout << "Length: " << GetArrayLength2(array) << std::endl; return 0;}输出
xxxxxxxxxxLength: 5Length: 5字节对齐
详细内容请参考:字节对齐与填充规则
备注:根据实际情况打开(存取速度优先)、关闭(节省内存空间)字节对齐。
目的:为了加快 CPU 访问数据的速度,将数据在内存中按照一定规律做字节对齐。
简单描述对齐与填充机制:
- 每个成员变量的首地址,必须是它的类型的对齐值的整数倍,如果不满足,它与前一个成员变量之间要填充(padding)一些无意义的字节来满足
- 整个结构体的大小,必须是该结构体中所有成员的类型中对齐值最大者的整数倍,如果不满足,在最后一个成员后面填充一些无意义的字节来满足
更改 C 编译器的缺省字节对齐方式
在缺省情况下,C 编译器为每一个变量或是数据单元按其自然对齐条件分配空间。一般地,可以通过下面的方法来改变缺省的对齐条件:
- 使用伪指令 #pragma pack (n),C 编译器将按照 n 个字节对齐;使用伪指令 #pragma pack (),取消自定义字节对齐方式
- __attribute((aligned (n))),让所作用的结构成员对齐在 n 字节自然边界上。如果结构中有成员的长度大于 n,则按照最大成员的长度来对齐
- __attribute__ ((packed)),取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐
举例
- 缺省字节对齐方式
xxxxxxxxxxstruct Data{ char c; long val; char data[0];};int main(){ printf("sizeof(Data): %d\n", sizeof(Data)); return 0;}输出
xxxxxxxxxxsizeof(Data): 16- __attribute__ ((packed)) 取消优化对齐
xxxxxxxxxxstruct Data{ char c; long val; char data[0];}__attribute__ ((packed));int main(){ printf("sizeof(Data): %d\n", sizeof(Data)); return 0;}输出
xxxxxxxxxxsizeof(Data): 9大端小端
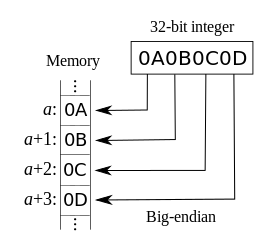
对于 32 位的整数,大端机器会在内存的低地址存储高位,在高地址存储低位。
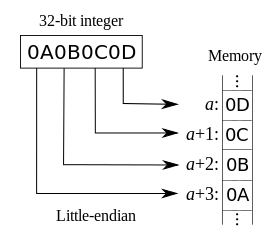
小端机器恰好相反,内存的低地址存储低位,在高地址存储高位。
大端表示法和人的直观比较相符,从低地址向高地址看过去,就是原先的数;小端表示法更便于计算机的操作,地址增加和个十百千万的增加是一致的。
可以通过如下两种方法判断机器属于大端或小端
xxxxxxxxxx int32_t i = 0x11223344; std::cout << ((*((char *)&i) == 0x11) ? "Big Endian" : "Little Endian") << std::endl;xxxxxxxxxxunion { int32_t i; char c; }u; u.i = 0x11223344; std::cout << ((u.c == 0x11) ? "Big Endian" : "Little Endian") << std::endl;变长数组
在实际的编程中,我们经常需要使用变长数组,但是 C 语言并不支持变长的数组。此时,我们可以使用结构体的方法实现 C 语言变长数组。
xxxxxxxxxxstruct Data{ char c; long val; char data[0];};在结构体中,data 是一个数组名;但该数组没有元素;该数组的真实地址紧随结构体 Data 之后,而这个地址就是结构体后面数据的地址。
xxxxxxxxxxstruct Data{ char c; long val; char data[0];};int main(){ char str[10] = "123456789"; Data *data = (Data*)malloc(sizeof(Data) + sizeof(str)); data->c = 'a'; data->val = 99; memcpy(data->data, str, strlen(str)); printf("sizeof(Data): %d\n", sizeof(Data)); printf("sizeof(*data): %d\n", sizeof(*data)); printf("c: %c, val: %d, data: %s\n", data->c, data->val, data->data); free(data); return 0;}输出
运行环境 x64 机器,默认开启字节对齐,示例中结构体按照 8 字节对齐,所以三个成员变量分别占用 8、8、0 字节,合计 16 字节。
xxxxxxxxxxsizeof(Data): 16sizeof(*data): 16c: a, val: 99, data: 123456789赋值运算符方法优先处理自赋值
在实现赋值运算时,需要先判断是否是自赋值。如果赋值运算符操作的两个对象实际是同一个对象,直接返回即可。
xxxxxxxxxxT& operator= (const T& that){ if (this == &that) return *this; // handle assignment here return *this;}PIMPL 指向实现的指针
PIMPL(pointer to implementation),即,指向实现的指针,是一种常用的,用来对“类的接口与实现”进行解耦的方法。这个技巧可以避免在头文件中暴露私有细节,因此是促进 API 接口与实现保持完全分离的重要机制。由于PIMPL 解除了接口与实现之间的耦合关系,从而降低文件间的编译依赖关系,PIMPL 也因此常被称为“编译期防火墙“ 。
主要优点
- 降低耦合
- 信息隐藏:真正实现依赖于私有指针完成
- 降低编译依赖,提高编译速度:可减少编译冲突
- 接口与实现分离
使用场景
一般来说,研发部基础平台组负责基础组件的开发,然后提供给业务组使用。因此,基础组件的接口不需要暴露过多的实现细节,同时,实现发生变化时,最好能够做到业务组不需要重新编译所有使用到基础组件的代码,否则将极大地增加学习、使用成本。例如,基础平台组提供跨平台的线程库,最开始只提供 支持 Windows,后续需要支持 Linux;或者需要在类中添加一个私有成员变量,如果直接在接口层实现,将导致 Windows 平台相关的所有代码需要重新编译。此时,利用 PIMPL 即可解决如上问题。
示例
定义一个 Book 类,包含一个成员变量。
xxxxxxxxxxclass Book{public: void Print();private: std::string m_contents;};对于使用者而言,只需要关注 Print(),但是如果我们给 Book 类添加一个成员变量
xxxxxxxxxxclass Book{public: void Print();private: std::string m_contents; std::string m_title;};虽然 Print() 接口本身不变,但是使用者需要重新编译所有使用到 Book 类的源码。此时,通过 PIMPL 可以得到解决。
- 提供接口的头文件 public.h
xxxxxxxxxx// public.hclass Book{public: void Print();private: class BookImpl; BookImpl *m_impl;};- 私有实现相关的头文件 private.h
xxxxxxxxxx// private.hclass Book::BookImpl{public: void Print();private: std::string m_contents; std::string m_title;};- 实现源文件
xxxxxxxxxxBook::Book() : m_impl(new BookImpl()){}Book::~Book(){ delete m_impl;}void Book::Print(){ m_impl->Print();}void Book::BookImpl::Print(){ std::cout << "print from BookImpl" << std::endl;}- 对于使用者而言
xxxxxxxxxxint main(){ Book book; book.Print(); return 0;}RAII
RAII 全称是“Resource Acquisition is Initialization”,直译过来是“资源获取即初始化”,也就是说在构造函数中申请分配资源,在析构函数中释放资源。因为 C++ 的语言机制保证了,当一个对象创建的时候,自动调用构造函数,当对象超出作用域的时候会自动调用析构函数。所以,在 RAII 的指导下,我们应该使用类来管理资源,将资源和对象的生命周期绑定。
RAII 技术被认为是 C++ 中管理资源的最佳方法,进一步引申,使用 RAII 技术也可以实现安全、简洁的状态管理,编写出优雅的异常安全的代码。
资源管理
智能指针(std::shared_ptr 和 std::unique_ptr)即 RAII 最具代表的实现,使用智能指针,可以实现自动的内存管理,再也不需要担心忘记 delete 造成的内存泄漏。
内存只是资源的一种,在这里我们讨论一下更加广义的资源管理。比如说文件的打开与关闭、windows 中句柄的获取与释放等等。按照常规的 RAII 技术需要写一堆管理它们的类,有的时候显得比较麻烦。但是如果手动释放,通常还要考虑各种异常处理,比如说:
xxxxxxxxxxvoid function(){ FILE *f = fopen("test.txt", 'r'); if (.....) { fclose(f); return; } else if(.....) { fclose(f); return; } fclose(f); //......}
xxxxxxxxxxclass ScopeGuard{public: explicit ScopeGuard(std::function<void()> f) : handle_exit_scope_(f){}; ~ScopeGuard(){ handle_exit_scope_(); }private: std::function<void()> handle_exit_scope_;};int main(){ { A *a = new A(); ON_SCOPE_EXIT([&] {delete a; }); //...... } { std::ofstream f("test.txt"); ON_SCOPE_EXIT([&] {f.close(); }); //...... } system("pause"); return 0;}当 ScopeGuard 对象超出作用域,ScopeGuard 的析构函数中会调用 handle_exit_scope_ 函数,也就是 lambda 表达式中的内容,所以在 lambda 表达式中填上资源释放的代码即可,多么简洁、明了。既不需要为每种资源管理单独写对应的管理类,也不需要考虑手动释放出现各种异常情况下的处理,同时资源的申请和释放放在一起去写,永远不会忘记。
状态管理
RAII 另一个引申的应用是可以实现安全的状态管理。一个典型的应用就是在线程同步中,使用 std::unique_lock 或者std::lock_guard 对互斥量 std:: mutex 进行状态管理。通常我们不会写出如下的代码:
xxxxxxxxxxstd::mutex mutex_;void function(){ mutex_.lock(); //...... mutex_.unlock();}因为,在互斥量 lock 和 unlock 之间的代码很可能会出现异常,或者有 return 语句,这样的话,互斥量就不会正确的unlock,会导致线程的死锁。所以正确的方式是使用 std::unique_lock 或者 std::lock_guard 对互斥量进行状态管理:
xxxxxxxxxxstd::mutex mutex_;void function(){ std::lock_guard<std::mutex> lock(mutex_); //......}在创建 std::lock_guard 对象的时候,会对 std::mutex 对象进行 lock,当 std::lock_guard 对象在超出作用域时,会自动std::mutex 对象进行解锁,这样的话,就不用担心代码异常造成的线程死锁。
总结
通过上面的分析可以看出,RAII 的核心思想是将资源或者状态与对象的生命周期绑定,通过 C++ 的语言机制,实现资源和状态的安全管理。理解和使用 RAII 能使软件设计更清晰,代码更健壮。
心跳实现
应用层自己实现的心跳包
由应用程序自己发送心跳包来检测连接是否正常,大致的方法是:服务器在一个 Timer 事件中定时向客户端发送一个短小精悍的数据包,然后启动一个低级别的线程,在该线程中不断检测客户端的回应, 如果在一定时间内没有收到客户端的回应,即认为客户端已经掉线;同样,如果客户端在一定时间内没有收到服务器的心跳包,则认为连接不可用。
TCP 的 KeepAlive 保活机制
因为要考虑到一个服务器通常会连接多个客户端,因此由用户在应用层自己实现心跳包,代码较多 且稍显复杂,而利用 TCP/IP 协议层为内置的 KeepAlive 功能来实现心跳功能则简单得多。 不论是服务端还是客户端,一方开启 KeepAlive 功能后,就会自动在规定时间内向对方发送心跳包, 而另一方在收到心跳包后就会自动回复,以告诉对方我仍然在线。 因为开启KeepAlive功能需要消耗额外的宽带和流量,所以 TCP 协议层默认并不开启 KeepAlive 功能,尽管这微不足道,但在按流量计费的环境下增加了费用,另一方面,KeepAlive 设置不合理时可能会 因为短暂的网络波动而断开健康的 TCP 连接。并且,默认的 KeepAlive 超时需要 7,200,000 MilliSeconds, 即 2 小时,探测次数为 5 次。对于很多服务端应用程序来说,2 小时的空闲时间太长。因此,我们需要手工开启 KeepAlive 功能并设置合理的 KeepAlive 参数。
warning: operation on 'i' may be undefined [-Wsequence-point]
在如下表达式中 j = ++ i % 10,根据操作符优先级,可以正确处理先自增,再求余,但编译器仍会提示如下错误
xxxxxxxxxxwarning: operation on 'i' may be undefined [-Wsequence-point]对于表达式 j = ++ i % 10,编译器将进行分解
- Load variable i to register α.
- Increment value in α.
- Save remainder of dividing α by 10 to register β.
- Save β to j.
- Save α to i.
问题在于,编译器可能按照另外一种分解方式,将第四步与第五步进行交换。即,你所使用的编译器实际采用哪种分解方式是不确定的。虽然交换第四步与第五步,不会影响最终 j 的结果,但是,更普遍地说,如果表达式变为 i = ++ i % 10,编译器同样存在上述两种分解方式,此时不同的分解方式将导致最终 i 的结果不同。
严格弱序
什么是严格弱序?
C++ 关联容器的有序容器对元素关键字的类型有要求,元素关键字的类型必须定义了严格弱序(strick weak ordering)。拿内置类型来说,C++都定义了“<”操作符,这就是一个严格弱序,而“<=”就不是一个严格弱序。
严格弱序有什么用?
对于内置类型我们自然可以有<、>、=来判断两个值的大小关系,而对于自定义的类类型,为它定义三种比较操作符是没有必要的,只用一个严格弱序(这里就用<为例)就可以表示两个元素三种大小关系。
| 数学表达式 | 只用小于操作符实现 |
|---|---|
| a < b | a < b |
| a > b | b < a |
| a = b | !(a < b) && !(b < a) |
严格弱序的三条要求
- 两个关键字不能同时“严格弱序”于对方
- 如果 a“严格弱序”于 b,且 b“严格弱序”于 c,则 a 必须“严格弱序”于 c
- 如果存在两个关键字,任何一个都不“严格弱序”于另一个,则这两个关键字是相等的
我们定义一个具体的函数来说明它是怎么满足和不满足严格弱序要求的,以及不满足严格弱序有什么后果
xxxxxxxxxx//定义一个结构体,该结构体没有提供严格弱序操作,必须额外为它定义一个严格弱序操作struct MyStruct{ int val; MyStruct(int _val):val(_val){}};//定义两个“我们所期望的严格弱序操作”bool Compare1(const MyStruct &a, const MyStruct &b){ return a.val < b.val;}//虽然很容易看出 Compare2 并不是一个严格弱序操作//但我们站在编译器的角度,用上面的三条要求来判别bool Compare2(const MyStruct &a, const MyStruct &b){ return a.val <= b.val;}| a.val | b.val | 逻辑大小 | C1(a, b) | C1(b, a) | !C1(a, b) && !C1(b, a) |
|---|---|---|---|---|---|
| 1 | 2 | a < b | true | false | false |
| 2 | 1 | a > b | false | true | false |
| 1 | 1 | a = b | false | false | true |
| a.val | b.val | 逻辑大小 | C2(a, b) | C2(b, a) | !C2(a, b) && !C2(b, a) |
|---|---|---|---|---|---|
| 1 | 2 | a < b | true | false | false |
| 2 | 1 | a > b | false | true | false |
| 1 | 1 | a = b | true | true | false |
上述 Compare2 方法判断相等的逻辑始终为 false,判断错误
非严格弱序方法带来什么问题?
有序关联容器不允许存在相同的关键字,在用 Compare2 判断时,会认为相同的关键字是不相等的,因此会将两个相同的关键字插入容器中,这个行为是未定义的